Exploiting GitHub Actions
I’m a contributor to the open-source keyboard firmware ZMK, which is a firmware that runs on custom, usually wireless keyboards. It turns electrical keypresses into real output to your computer with a bunch of cool features and customizations. In our project, we house widely available custom “boards” and “shields”. “Boards” are defined as the part of the keyboard that has the microprocessor running the firmware, and “shields” are the keyboard looking circuit board that a “board” plugs into. With every commit to the main repository and pull requests we build firmware for every single board and shield combination using GitHub Actions.
For those unfamiliar, GitHub Actions is a Continuous Integration/Delivery. More simply, it allows us to run build scripts on every commit to make sure everything still works with the new changes committed. This is free to open source projects with some limitations, which we’ll see soon.
The Problem#
ZMK has grown in popularity, and today we’re sitting at 13 boards and 44 shields, which is awesome. For our GitHub Actions workflows, we utilize what’s called a build matrix to generate all of the different firmware files required. This allows us to set all the boards as one dimension and all the shields as the other, and then it builds every single combination possible, which is perfect… except for one thing. GitHub Actions limits matrix builds to 256 maximum jobs. Considering today we have 528 combinations, we exceed this limit, and it’s not going to ever get better. We need a solution to be able to continue building every combination.
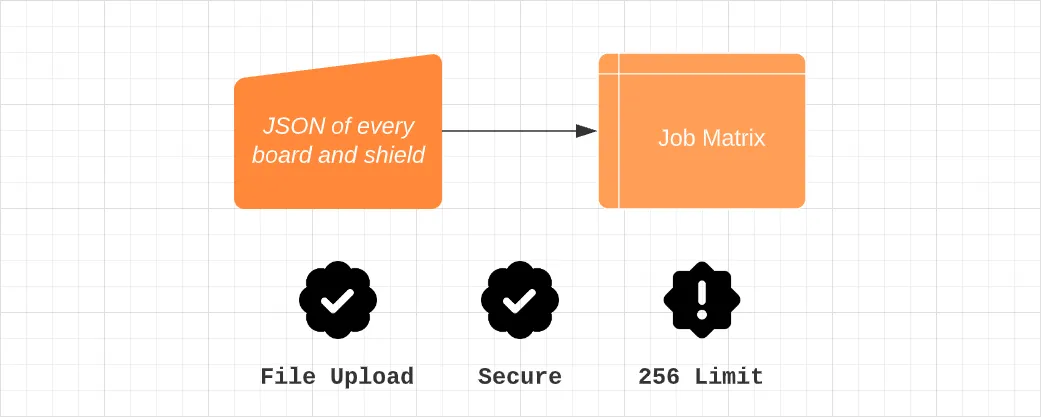
Analyzing Possible Solutions#
The first thing you might think is, why not just loop through every combination in one job instead of running a different job for each firmware file? This isn’t a bad train of thought, but we have to consider our limitations.
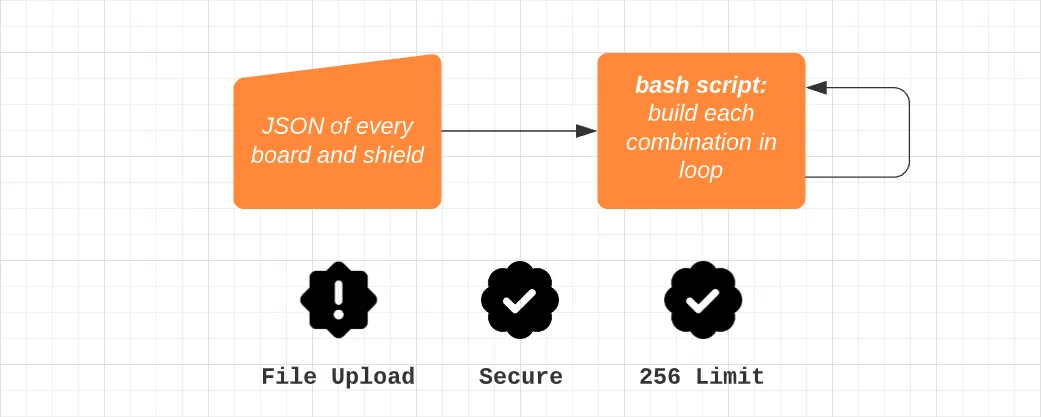
We have to use basic bash scripting to complete these loops, and feeding these combinations via JSON/YAML is not an easy task. The other major issue is that we need to upload each build file as an artifact so users can find and download them. Unfortunately, there isn’t an easy way to upload unique artifacts in a loop since you can’t call the artifact upload action from inside a raw bash script.
When I looked into this problem I first tried to remove the build matrix portion entirely. In my mind, there was no way of getting around the 256 limit. I turned to the GitHub Actions API, which has a way to invoke workflow runs with parameters. I thought this was perfect to run an unlimited amount of jobs since we’re working outside of the matrix job limit and we can queue however many workflows as we want.
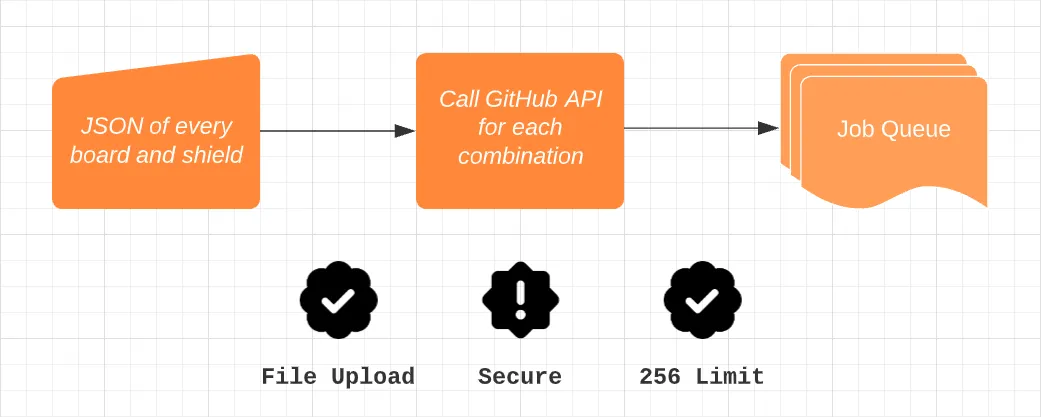
This was looking like a good solution until I realized one flaw. To call these API endpoints we needed to pass a privileged API key into the GitHub Action script. While we can hide the key fairly effectively, the project is open source, and we run these scripts on every pull request making it an easy target to do other nefarious activities.
With direct API calls off the table, I turned back to looping through every combination as a possible solution. This time I was trying to figure out how I can more easily walk through all the combinations and upload every file individually. I ultimately couldn’t figure out a way to do it in bash scripting, and then I stumbled upon a GitHub action that solved all my problems by misusing it; GitHub Script.
GitHub Script#
The GitHub Script action’s tagline is “Write workflows scripting the GitHub API in JavaScript”. This action is supposed to be used to interact with GitHub issues, pull requests, and other GitHub API elements. Crucially, it gives a sandboxed environment that’s still privileged and contains the current workflow’s context. This allows us to upload file artifacts arbitrarily whenever we want, including in loops.
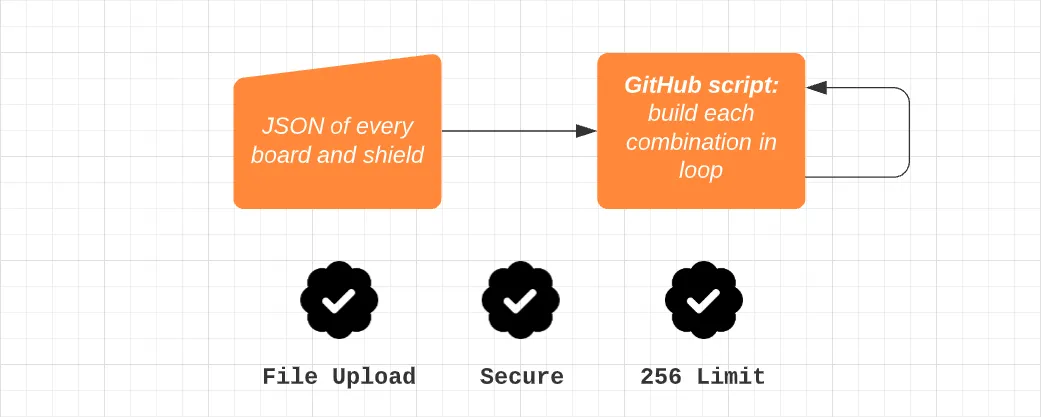
Instead of using it to interact with GitHub API elements, I use it to run the same scripts we ran in the bash script to build each combination and then upload the file artifact, perfect!
One issue with this solution though, is that we lost all parallelization. This means we have to build all 528 files one at a time, which is pretty slow. To improve upon this I decided to return the job matrix, but use it differently this time. I now use it to create a new job for each board, not for each combination. So we now create 13 board jobs that run all the possible combinations for that specific board using GitHub Script.
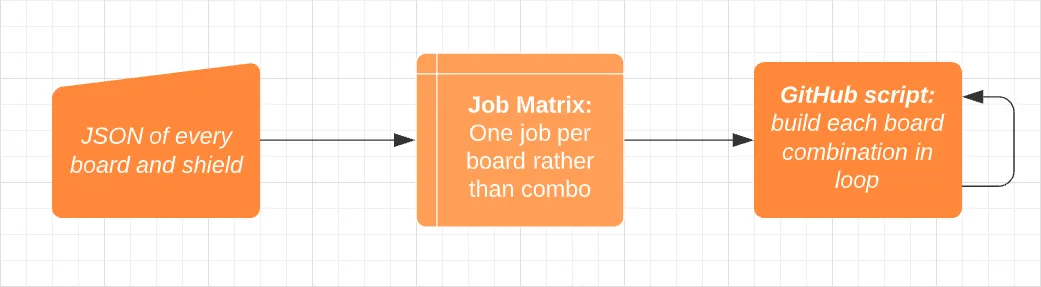
With this solution, we can build 528 firmware files just as fast as we used to build only 256 before. I’d consider this a huge success that should last for years to come. That is until we get 256 boards…
Other Improvements#
While solving this major problem for our build script, I also overhauled a couple of other parts of our build script that may interest you.
- We used to manually write every board/shield in a list inside the build script to keep track of what combinations to build. This was an extra file to maintain and caused tons of merge issues as people were creating pull requests simultaneously. We’ve transitioned to a system that reads in what boards and shields there are dynamically by walking the board/shield directory of the project.
- We used to build around 256 firmware files on every single commit no matter what the change was. It covered everything, but it was inefficient and caused hours of pileups of queued jobs. The new script checks whether the changes change a board/shield or change something core in the firmware. If there is a board/shield change, it builds every board/shield combination that’s affected by the change. If there’s a core change, it builds a short list of boards/shields that cover nearly every use case. This has cut down on almost all of our queued job issues and made our checks complete in a fraction of the time. We also build every combination nightly to make sure every combination has fresh firmware with all the new features.
If you’re curious to see what these changes looked like you can see the pull request here.